最近,自然语言处理工具 ChatGPT 彻底出圈火爆全网,显然自然语言处理和深度学习将是下一步人工智能发展的趋势之一。于是,我尝试跟着 MIT 大神 Keith Galli 的 Tutorial 一起,初学使用 Python 库进行自然语言处理,在一个个例子中深入了解自然语言处理的主要概念。以下为我在学习和实战练习过程中所做的笔记,可供参考。
一、Bag-of-words
机器学习算法不能直接处理原始文本,文本必须转换为数字向量。在语言处理中,向量 x 来自文本数据,以反映文本的各种语言特性。这称为特征提取或特征编码。Bag-of-words(词袋)模型就是一种流行且简单的文本数据特征提取方法,在这种方法中,我们将每个单词计数视为一个特征。词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
第 1 步:定义一些训练语句
1 | class Category: |
第 2 步:使用机器学习库 scikit-learn 拟合模型,将每个自由文本文档转换为一个向量,我们可以将其用作机器学习模型的输入或输出。最简单的评分方法是将单词的存在标记为布尔值,0 表示不存在,1 表示存在,用向量中的一个位置对每个词进行评分:
1 | from sklearn.feature_extraction.text import CountVectorizer |
第 3 步:使用线性 SVM 模型构建一个简单的文本分类器:
1 | from sklearn import svm |
第 4 步:在经过训练的模型上测试新语句:
1 | test_x = vectorizer.transform(['i love the books']) # 向量化新语句 |
二、Word Vectors
词向量(Word Vectors)模型是考虑词语位置关系的一种模型,通过大量语料的训练,将每一个词语映射到高维度的向量当中,通过求余弦的方式,可以判断两个词语之间的关系。把词映射为实数域向量的技术也叫词嵌入(Word Embedding)。随着优秀的词向量模型(Word2Vec、ELMo、Bert 等)的出现,推动了 NLP 领域飞跃式的发展。
spaCy 是世界上最快的工业级自然语言处理工具。 支持多种自然语言处理基本功能,包括分词、词性标注、词干化、命名实体识别、名词短语提取等等。
1 | !pip install spacy |
使用词向量构建文本分类模型:
1 | import spacy |
使用我们的模型预测新的语句:
1 | test_x = ["I love the books"] |
三、Regexes
正则表达式(Regexes)本质上是一种嵌入在 Python 中并通过 re 模块提供的高度专业化的微型编程语言。 使用这种小语言,您可以为要匹配的可能字符串集指定规则; 该集合可能包含英文句子、电子邮件地址、TeX 命令或任何您喜欢的内容。 然后,您可以提出诸如“此字符串是否与模式匹配?”或“此字符串中任何位置的模式是否匹配?”之类的问题。 您还可以使用 RE 修改字符串或以各种方式将其拆分:
1 | import re |
四、Stemming/Lemmatization
Python NLTK 中的词干提取(Stemming)和词形还原(Lemmatization)是自然语言处理的文本规范化技术。这些技术广泛用于文本预处理。词干化和词形还原之间的区别在于,词干化更快,因为它在不知道上下文的情况下切割单词,而词形还原更慢,因为它在处理之前知道单词的上下文:
1 | import nltk |
词干提取是一种将句子中的一组单词转换为序列以缩短其查找时间的技术。在这种方法中,具有相同含义但根据上下文或句子有一些变化的词被归一化。换句话说,只有一个词根,但同一个词有许多变体。例如,词根是 eat,它的变体是 eats, eating, eaten and like so。同样,借助 Python 中的词干提取,我们可以找到任何变体的词根。
NLTK 有一个名为 PorterStemmer 的算法。该算法接受标记化词列表并将其词干化为词根:
1 | from nltk.tokenize import word_tokenize |
词形还原是根据词义和上下文查找词词元的算法过程。词形还原通常是指对单词进行词法分析,旨在去除屈折词尾。它有助于返回称为词条的单词的基本形式或字典形式。
Lemmatization 优于 Stemming,因为词干算法通过从单词中删除后缀来工作。从广义上讲,就是切断单词的开头或结尾。相反,Lemmatization 是一个更强大的操作,它考虑了单词的形态分析。它返回作为所有屈折形式的基本形式的引理。需要深入的语言知识来创建词典和寻找单词的正确形式。词干提取是一种通用操作,而词形还原是一种智能操作,可以在字典中查找正确的形式。因此,词形还原有助于形成更好的机器学习特征。
NLTK Lemmatization 方法基于 WorldNet 的内置 morph 函数:
1 | from nltk.stem import WordNetLemmatizer |
五、Stopwords
停用词(Stopwords)是搜索引擎被编程为忽略的常用词(例如 the、a、an、in),无论是在索引条目进行搜索时还是在检索条目时作为搜索查询的结果。 我们不希望这些词占用我们数据库中的空间,或占用宝贵的处理时间。为此,我们可以通过存储您认为是停用词的单词列表来轻松删除它们。
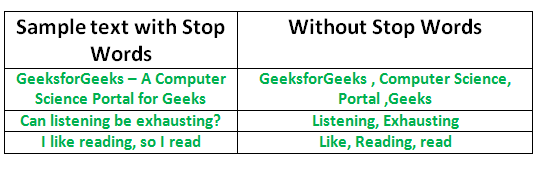
Python 中的 NLTK(自然语言工具包)有一个以 16 种不同语言存储的停用词列表,标记化,然后删除停用词:
1 | from nltk.tokenize import word_tokenize |
六、TextBlob
TextBlob 是一个用 Python 编写的开源的文本处理库。它可以用来执行很多自然语言处理的任务,比如,词性标注,名词性成分提取,情感分析,文本翻译等等。
1 | !python -m textblob.download_corpora |
使用 TextBlob 进行拼写更正、情感和词性标注:
1 | from textblob import TextBlob |
七、State-of-the-art Models
Recurrent Neural Networks (RNNs) for text classification
循环神经网络(Rerrent Neural Network, RNN)是一种专门处理序列信息的具有时间依赖的网络。
Transformer architectures (attention is all you need)
Transformer 模型基于 encoder-decoder 架构,抛弃了传统的 RNN、CNN 模型,仅由 Attention 机制实现,并且由于 encoder 端是并行计算的,训练时间大大缩短。
Transformer 模型广泛应用于 NLP 领域,机器翻译、文本摘要、问答系统等等,目前火热的 Bert 模型就是基于 Transformer 模型构建的。
使用 spaCy 来使用 BERT 模型:
1 | !pip install spacy-transformers |
使用 Transformers/BERT 编写分类模型:
1 | import spacy |